N_编程设计手记
手记传送门:
手记(编程/设计)
手记(科学/文学)
手记(电子/硬件)
手记(游戏/娱乐)
PS:可以页内查找关键词找到相应位置,或点开目录浏览。
S_小工具集
Excel TEXTJOINA 宏
用于2019前的Excel版本没有TEXTJOIN函数
TEXTJOINA.zip
数据滤波算法集合
一、限幅滤波法
实现步骤:
- 根据经验法选择最大偏差值E。
- |value_now - value_before| <= E,value_now有效,否则其无效且将其舍弃,最后令value_now = value_before。
实现程序:
#define E 10 //value取值范围为90~110
int value_init = 100;
int filter(int value_now)
{
if ((value_now - value_before > E) || (value_before - value_now) > E)
{
return value_before;
}
return value_now;
}滤波优缺点:
- 优:可克服偶然误差。
- 缺:无法抑制周期性干扰;平滑度差。
二、中位值滤波法
实现步骤:
- 连续采样N次(N为奇数)
- 将其排序(任选一种排序算法)
- 只取中间值
实现程序:
#define N 5 //根据传感器性能和主控芯片性能进行设置
int filter(void)
{
int *buf = (int*)malloc(N * sizeof(int));
char count, i, j, temp;
for (count = 0; count < N; count++)
{
buf[count] = get_val(); //获取新的采样值
delay(); //采样间隔
}
for (j = 0; j<N - 1; j++) //采用冒泡排序
{
for (i = 0; i<N - j - 1; i++)
{
if (buf[i]>buf[i + 1])
{
temp = buf[i];
buf[i] = buf[i + 1];
buf[i + 1] = temp;
}
}
}
freebuf); //释放内存块
return buf[(N - 1) / 2]; //返回中间值
}滤波优缺点:
- 优:可克服偶然误差;对缓慢变化的数据有很好的滤波效果。
- 缺:不适用于快速变化的数据。
三、算术平均滤波法
实现步骤:
- 取N个数据求均值
- N大 --> 平滑度高,灵敏度低
- N小 --> 平滑度低,灵敏度高
- 通常,流量N=12,压力N=4,液面,N=412,温度N=14
实现程序:
#define N 10
int filter(void)
{
int sum = 0, count;
for (count = 0; count < N; count++)
{
sum += get_val(); //获取采样值并求和
delay();
}
return (sum / N);
}滤波优缺点:
- 优:适用于对一般具有随机干扰的信号进行滤波,信号会在此平均值附近上下波动。
- 缺:不适用于测量速度慢或要求数据计算快的实时控制;浪费运行内存。
四、中位值平均滤波法(二三结合)
实现步骤:
- 采样N个数据并排序
- 去掉数组头和尾(去除最大最小值)
- 计算(N-2)个数的平均数
实现程序:
#define N 12
int get_val(); //传感器采集数据函数
int filter()
{
char count, i, j;
int buf[N];
int sum = 0, temp;
for (count = 0; count < N; count++)
{
buf[count] = get_val();//获取采样值
delay();
}
for (i = 0; i < N - 1; i++) //冒泡排序
{
for (j = 0; j < N - j - 1; j++)
{
if (buf[i] > buf[i + 1])
{
temp = buf[i];
buf[i] = buf[i+1];
buf[i + 1] = temp;
}
}
}
for (count = 1; count < N - 1; count++)
{
//由于数列已经排序了,所以去掉头尾就是去掉最小值和最大值
sum += buf[count];
}
return (sum / (N - 2));
}滤波优缺点:
- 优:对于偶然出现的脉冲性干扰;可消除由其引起的采样值偏差;对周期干扰有良好的抑制作用;平滑度高;适于高频振荡的系统。
- 缺:浪费运行内存。
五、限幅平均滤波法(一三结合)
实现步骤:
- 对数据进行限幅并对有效数据求平均值。
实现程序:
#define E 10 //误差允许值
#define N 12 //采样数据数目
char value_init = 100; //采样参考值
char temp;
char getval(); //传感器读取数据函数
char filter(void)
{
char i, value_now, value_before, sum, count = 0;
//count:防止传感器出错而陷入死循环
char *buf = (char*)malloc(N * sizeof(char));
while (1)//直到取得有效值为止
{
temp = getval();
if ((temp - value_init >E) || (temp - value_init <E))
{
temp = getval();
count++;
if (count == 5)
{
buf[0] = value_init;
break;
}
}
else
{
buf[0] = temp; //获取采样值用作上一次的值
break;
}
}
for (i = 1; i < N; i++) //过滤超出范围的值
{
value_now = getval(); //获取采样值用作上一次的值
if ((value_now - buf[i - 1]) > E || (buf[i - 1] - value_now) > E)
{
buf[i] = buf[i - 1]; //本次数据等于上一数据
}
else
buf[i] = value_now; //本次数据有效
}
for (i = 0; i < N; i++)
{
buf[i] = buf[i + 1];
sum += buf[i];
}
return (sum / N);
}滤波优缺点:
- 优:限幅+滤波的优点。
- 缺:浪费运行内存。
六、递推平均滤波法
实现步骤:
- 将N个数据看做(FIFO)队列,每次采样到的数据替换掉最先进入队列的数据,最后求平均值。
实现程序:
#define N 12
int buf[N]; //全局变量,存储N个数据
static char i = 0;
int get_val();
int filter(void)
{
char count;
int sum = 0;
if (i == N) i = 0;
//当数据大于数组长度,替换数据组的最先进入的一个数据相当于环形队列更新(FIFO)
buf[i++] = get_val();
for (count = 0; count < N; count++)
sum += buf[count];
return(sum / N);
}滤波优缺点:
- 优:对周期性干扰有良好的抑制作用,平滑度高;适用于高频振荡的系统。
- 缺:灵敏度低;对偶然出现的脉冲性干扰的抑制作用较差;不易消除由于脉冲干扰所引起的采样值偏差; 不适用于脉冲干扰比较严重的场合;浪费运行内存。
七、加权递推平均滤波法(六-改进版)
实现步骤:
- 越接近现在时刻的数据,权取得越大。(给予新采样值的权系数越大,则灵敏度越高,但信号平滑度越低。)
实现程序:
#define N 12
const char coe[] = { 1,2,3,4,5,6,7,8,9,10,11,12 }; //权值对照表
const char sum_coe = 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12;//权和
//也可用递归方式生成这两个数组
char filter()
{
char i;
char value_buf[N];
int sum = 0;
for (i = 0; i < N; i++)
{
value_buf[i] = get_val();//获取采样数据
delay();
}
for (i = 0; i < N; i++)
sum += value_buf[i] * coe[i];
return sum / sum_coe;
}滤波优缺点:
- 优:适用于有较大纯滞后时间常数的控制对象;采样周期较短的系统。
- 缺:对于纯滞后时间常数较小,采样周期较长;变化缓慢的信号不能迅速反应系统当前所受干扰的严重程度,滤波效果差。
八、消抖滤波法
实现步骤:
- 设置一个滤波计数器。
- 将每次采样值与当前有效值比较:如果采样值==当前有效值,则返回上一个有效值;
- 如果采样值!=当前有效值,则计数器+1,并判断计数器是否>=上限N(溢出);
- 如果计数器溢出,则将本次值替换当前有效值,并清计数器。
实现程序:
#define N 12
char get_val();
char filter()
{
char count = 0;
char value_now;
char value_before = get_val(); //获取上一个采样数据
while (value_now != value_before)
{
value_before = value_now;
count++;
if (count >= N)
return value_now;
delay();//适当延时
value_now = get_val();//获取下一个采样数据
}
return value_before;
}滤波优缺点:
- 优:对于变化缓慢的被测参数有较好的滤波效果, 可避免在临界值附近控制器的反复开/关跳动或显示器上数值抖动。
- 缺:对于快速变化的参数不宜; 如果在计数器溢出的那一次采样到的值恰好是干扰值,则会将干扰值当作有效值导入系统。
九、一阶滞后滤波法
实现步骤:
- 一阶低通滤波法采用本次采样值与上次滤波输出值进行加权,得到有效滤波值,使得输出对输入有反馈作用。
实现程序:
#define thresholdValue 10 //阀门值
#define N 10 //数据量
float dataArr[N] = { 99,102,108,89,98,86,89,90,93,105 }; //假设获得的数据
char flag0 = 0, flag1 = 0; //前一次比较与当前比较的方向位
float abs(float first, float second) //求两个数的绝对值
{
float abs_val;
if(first>second)
{
abs_val = first - second;
flag1 = 0;
}
else
{
abs_val = second - first;
flag1 = 1;
}
return abs_val;
}
void filter(void)
{
char i = 0, filterCount = 0, coeff = 0; //filterCount:滤波计数器 coeff:滤波系数
float Abs = 0.00;
for (i = 1; i < N; i++)
{
Abs = abs(dataArr[i - 1], dataArr[i]);
if (!flag1^flag0) //异或
{
filterCount++;
if (Abs >= thresholdValue)
{
filterCount += 2;
}
if (filterCount >= 12)
filterCount = 12;
coeff = 20 * filterCount; //确定一阶滤波系数
}
else//消抖
coeff = 5;
//一阶滤波算法
if (flag1 == 0)//当前值小于前一个值
dataArr[i] = dataArr[i - 1] - coeff*(dataArr[i - 1] -
dataArr[i]) / 256;
else
dataArr[i] = dataArr[i - 1] + coeff*(dataArr[i - 1] -
dataArr[i]) / 256;
filterCount = 0;
flag0 = flag1;
}
}滤波优缺点:
- 优: 对周期性干扰具有良好的抑制作用;适用于波动频率较高的场合。
- 缺:相位滞后;灵敏度低;滞后程度取决于a值大小;不能消除滤波频率高于采样频率的1/2的干扰信号。
十、卡尔曼滤波
实现步骤:
- 通过实时改变协方差来对系统进行修正。
实现程序:
/*------------------------------------------------------------------------------
| Kalman Filter equations
|
| state equation状态方程
| x(k) = A·x(k-1) + B·u(k) + w(k-1)
| 如果没有控制量则B·u(k)=0(如单纯测量温度湿度之类的)
|
| observations equation观测方程(传感器测得数据)
| z(k) = H·x(k) + y(k)
|
| prediction equations预测方程
| x(k|k-1) = A·x(k-1|k-1) + B·u(k)
| P(k|k-1) = A·P(k-1|k-1)·A^T + Q
|
| correction equations修正方程
| K(k) = P(k|k-1)·H^T·(H·P(k|k-1)·H^T + R)^(-1)
| x(k|k) = x(k|k-1) + K(k)·(z(k) - H·x(k|k-1))
| P(k|k) = (I - K(k)·H)·P(k|k-1)
------------------------------------------------------------------------------*/
/*
x和P只需要赋初值,每次迭代会产生新值;K用不着赋初值;
Q和R赋值以后在之后的迭代中也可以改。
x和P的初值是可以随便设的,强大的卡尔曼滤波器马上就能抹除不合理之处。
但需注意,P的初值不能为0,否则滤波器会认为已经没有误差了
R越大曲线越平滑,但会使滤波器变得不敏感,存在滞后
(Q和R取值也可以是时变的,可以识别跳变,可以自适应)
Q:过程噪声,Q增大,动态响应变快,收敛稳定性变坏
R:测量噪声,R增大,动态响应变慢,收敛稳定性变好
*/
#define KalmanQ 0.000001
#define KalmanR 0.0004
static double KalmanFilter(const double ResourceData, double ProcessNoiseQ, double MeasureNoiseR)
{
double R = MeasureNoiseR;
double Q = ProcessNoiseQ;
static double x_last=-60;
double x_mid = x_last;
double x_now;
static double p_last=1;
double p_mid;
double p_now;
double K;
x_mid = x_last; //x_last=x(k-1|k-1),x_mid=x(k|k-1)
p_mid = p_last; //p_mid=p(k|k-1),p_last=p(k-1|k-1),Q=过程噪声
K = p_mid / (p_mid + R);
x_now = x_mid + K*(ResourceData - x_mid);
p_now = (1 - K)*p_mid + Q;
p_last = p_now;
x_last = x_now;
return x_now;
}滤波优缺点:
- 优:能处理传感器噪声和过程噪声等。
- 缺:当运动目标长时间被遮挡时会存在目标跟踪丢失的情况 。
十一、其他滤波
(一)、IIR数字滤波器(Infinite Impulse Response Filter)
递归滤波器,也就是IIR数字滤波器,顾名思义,具有反馈。
(二)、FIR数字滤波器(Finite Impulse Response Filter)
有限长单位冲激响应滤波器,又称为非递归型滤波器,是数字信号处理系统中最基本的元件,它可以在保证任意幅频特性的同时具有严格的线性相频特性,同时其单位抽样响应是有限长的,因而滤波器是稳定的系统。因此,FIR滤波器在通信、图像处理、模式识别等领域都有着广泛的应用。它具有线性相位、容易设计的优点,但相对于IIR滤波器它需要更多的参数,因此DSP需要更多的计算时间,对DSP的实时性有影响。
从性能上来说,IIR滤波器传递函数包括零点和极点两组可调因素,对极点的惟一限制是在单位圆内。因此可用较低的阶数获得高的选择性,所用的存储单元少,计算量小,效率高。但是这个高效率是以相位的非线性为代价的。选择性越好,则相位非线性越严重。FIR滤波器传递函数的极点固定在原点,是不能动的,它只能靠改变零点位置来改变它的性能。所以要达到高的选择性,必须用较高的阶数;对于同样的滤波器设计指标,FIR滤波器所要求的阶数可能比IIR滤波器高5-10倍,结果,成本较高,信号延时也较大;如果按线性相位要求来说,则IIR滤波器就必须加全通网络进行相位校正,同样要大大增加滤波器的阶数和复杂性。而FIR滤波器却可以得到严格的线性相位。
从结构上看,IIR滤波器必须采用递归结构来配置极点,并保证极点位置在单位圆内。由于有限字长效应,运算过程中将对系数进行舍入处理,引起极点的偏移。这种情况有时会造成稳定性问题,甚至产生寄生振荡。相反,FIR滤波器只要采用非递归结构,不论在理论上还是在实际的有限精度运算中都不存在稳定性问题,因此造成的频率特性误差也较小。此外FIR滤波器可以采用快速傅里叶变换算法,在相同阶数的条件下,运算速度可以快得多。
另外,也应看到,IIR滤波器虽然设计简单,但主要是用于设计具有分段常数特性的滤波器,如低通、高通、带通及带阻等,往往脱离不了模拟滤波器的格局。而FIR滤波器则要灵活得多,尤其是他易于适应某些特殊应用,如构成数字微分器或希尔波特变换器等,因而有更大的适应性和广阔的应用领域。
从上面的简单比较可以看到IIR与FIR滤波器各有所长,所以在实际应用时应该从多方面考虑来加以选择。从使用要求上来看,在对相位要求不敏感的场合,如语言通信等,选用IIR较为合适,这样可以充分发挥其经济高效的特点;对于图像信号处理,数据传输等以波形携带信息的系统,则对线性相位要求较高。如果有条件,采用FIR滤波器较好。当然,在实际应用中可能还要考虑更多方面的因素。
- 不论IIR和FIR,阶数越高,信号延迟越大;同时在IIR滤波器中,阶数越高,系数的精度要求越高,否则很容易造成有限字长的误差使极点移到单位园外。因此在阶数选择上是综合考虑的。
————————————————
版权声明:本文为CSDN博主「SeanOY」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_33194301/article/details/87894883
修改 win10 右键“新建”菜单(原理、两种方法及注意事项)
操作
运行注册表编辑器(regedit.exe),分别进入 HKEY_CLASSES_ROOT\ 下的各后缀分支(比如 .doc),删除其下的 ShellNew 分支,即可删除相应的右键菜单。
原理
默认情况下,win10 会在用户每次单击右键后,系统弹出“新建”菜单之前,从\HKEY_CLASSES_ROOT\ 各后缀中提取 ShellNew 分支,自动生成 HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\Discardable\PostSetup\ShellNew\Classes 项目,然后“新建”菜单就根据该项目来生成。
注意事项
部分后缀的 ShellNew 隐藏在次级分支下。比如 .doc 后缀的 ShellNew 分支就隐藏在 Word.Document.8 分支底下,为 \HKEY_CLASSES_ROOT\.doc\Word.Document.8\ShellNew。
部分后缀存在不止一个 ShellNew 分支,则所有 ShellNew 分支均需删除。比如系统若同时安装了 MS Office 与 WPS,则 .doc 分支下的 WPS.DOC.6 分支里,也存在 ShellNew,即 \HKEY_CLASSES_ROOT\.doc\WPS.DOC.6\ShellNew。
若是不知道准确的后缀,可以参考HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\Discardable\PostSetup\ShellNew\Classes 项目。
经确认,本方法同时适用于 windows10、windows7。
其他方法
也可以通过禁止系统重置 HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\Discardable\PostSetup\ShellNew\Classes 项目的内容,来实现自定义右键菜单,包括排列顺序。具体参考下方资料。
参考
Win10 自定义右键新建菜单
windows10 怎么调整桌面右键菜单新建选项中的顺序
————————————————
版权声明:本文为CSDN博主「goocheez」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/goocheez/article/details/118692550
查看局域网内所有的IP
for /L %i IN (1,1,254) DO ping -w 2 -n 1 192.168.0.%i关于页面地址后面的“/”符号
www.0.com/floder和www.0.com/floder/一样吗?就访问而言,最终的效果是一样的,都是跳转到floder目录下的index.html,但是对于这个目录下页面的相对路径而言却不同。
- 当网址为
www.0.com/floder时,www.0.com/floder/index.html或目录下其他页面中的当前目录为网站根目录,也就是并没有跳转到floder目录下,此时如果使用了../索引的话是去floder的父目录的父目录,是引用不到的。- 当网址为
www.0.com/floder/时,www.0.com/floder/index.html或目录下其他页面中的当前目录为floder目录,此时使用了../去索引路径就会连接到floder父目录下的路径。- 示例:
https://mengze.top/MZtop/MV_韵风
https://mengze.top/MZtop/MV_韵风/
所以在其他页面进行页面跳转时,记得在目录后加上“/”。
Ubuntu忘记root密码(Hidden)
<!--

-->
递归与迭代的区别
1、“递归”是指函数/过程/子程序在运行过程序中直接或间接调用自身而产生的重入现像.。在计算机编程里,递归指的是一个过程:函数不断引用自身,直到引用的对象已知。
2、“迭代”的含义是:重复反馈过程的活动,其目的通常是为了逼近所需目标或结果。每一次对过程的重复称为一次“迭代”,而每一次迭代得到的结果会作为下一次迭代的初始值。
迭代——《明日边缘》
递归——《盗梦空间》
-- ForwardMe - 知乎
键盘键值表
| 虚拟键 | 十六进制值 | 十进制值 | 相应键盘或鼠标键 |
|---|---|---|---|
| VK_LBUTTON | 01 | 1 | 鼠标左键 |
| VK_RBUTTON | 02 | 2 | 鼠标右键 |
| VK_CANCEL | 03 | 3 | Ctrl-Break键 |
| VK_MBUTTON | 04 | 4 | 鼠标中键 |
| VK_BACK | 08 | 8 | Backspace键 |
| VK_TAB | 09 | 9 | Tab键 |
| VK_CLEAR | 0C | 12 | Clear键 |
| VK_RETURN | 0D | 13 | Enter键 |
| VK_SHIFT | 10 | 16 | Shift键 |
| VK_CONTROL | 11 | 17 | Ctrl键 |
| VK_MENU | 12 | 18 | Alt键 |
| VK_PAUSE | 13 | 19 | Pause键 |
| VK_CAPITAL | 14 | 20 | Caps Lock键 |
| VK_ESCAPE | 1B | 27 | Esc键 |
| VK_SPACE | 20 | 32 | Space键 |
| VK_PRIOR | 21 | 33 | Page Up键 |
| VK_NEXT | 22 | 34 | Page Down键 |
| VK_END | 23 | 35 | End键 |
| VK_HOME | 24 | 36 | Home键 |
| VK_LEFT | 25 | 37 | ←键 |
| VK_UP | 26 | 38 | ↑键 |
| VK_RIGHT | 27 | 39 | →键 |
| VK_DOWN | 28 | 40 | ↓键 |
| VK_SELECT | 29 | 41 | Select键 |
| VK_PRINT | 2A | 42 | Print键 |
| VK_EXECUTE | 2B | 43 | Execute键 |
| VK_SNAPSHOT | 2C | 44 | Print Screen键 |
| VK_INSERT | 2D | 45 | Ins键 |
| VK_DELETE | 2E | 46 | Del键 |
| VK_HELP | 2F | 47 | Help键 |
| VK_0 | 0x30 | 48 | 0键 |
| VK_1 | 0x 31 | 49 | 1键 |
| VK_2 | 0x 32 | 50 | 2键 |
| VK_3 | 0x 33 | 51 | 3键 |
| VK_4 | 0x 34 | 52 | 4键 |
| VK_5 | 0x 35 | 53 | 5键 |
| VK_6 | 0x 36 | 54 | 6键 |
| VK_7 | 0x 37 | 55 | 7键 |
| VK_8 | 0x 38 | 56 | 8键 |
| VK_9 | 0x 39 | 57 | 9键 |
| VK_A | 41 | 65 | A键 |
| VK_B | 42 | 66 | B键 |
| VK_C | 43 | 67 | C键 |
| VK_D | 44 | 68 | D键 |
| VK_E | 45 | 69 | E键 |
| VK_F | 46 | 70 | F键 |
| VK_G | 47 | 71 | G键 |
| VK_H | 48 | 72 | H键 |
| VK_I | 49 | 73 | I键 |
| VK_J | 4A | 74 | J键 |
| VK_K | 4B | 75 | K键 |
| VK_L | 4C | 76 | L键 |
| VK_M | 4D | 77 | M键 |
| VK_N | 4E | 78 | N键 |
| VK_O | 4F | 79 | O键 |
| VK_P | 50 | 80 | P键 |
| VK_Q | 51 | 81 | Q键 |
| VK_R | 52 | 82 | R键 |
| VK_S | 53 | 83 | S键 |
| VK_T | 54 | 84 | T键 |
| VK_U | 55 | 85 | U键 |
| VK_V | 56 | 86 | V键 |
| VK_W | 57 | 87 | W键 |
| VK_X | 58 | 88 | X键 |
| VK_Y | 59 | 89 | Y键 |
| VK_Z | 5A | 90 | Z键 |
| VK_LWIN | 5B | 91 | 左Windows键 |
| VK_RWIN | 5C | 92 | 右Windows键 |
| VK_APPS | 5D | 93 | 应用程序键 |
| VK_SLEEP | 5F | 95 | 休眠键 |
| VK_NUMPAD0 | 60 | 96 | 小数字键盘0键 |
| VK_NUMPAD1 | 61 | 97 | 小数字键盘1键 |
| VK_NUMPAD2 | 62 | 98 | 小数字键盘2键 |
| VK_NUMPAD3 | 63 | 99 | 小数字键盘3键 |
| VK_NUMPAD4 | 64 | 100 | 小数字键盘4键 |
| VK_NUMPAD5 | 65 | 101 | 小数字键盘5键 |
| VK_NUMPAD6 | 66 | 102 | 小数字键盘6键 |
| VK_NUMPAD7 | 67 | 103 | 小数字键盘7键 |
| VK_NUMPAD8 | 68 | 104 | 小数字键盘8键 |
| VK_NUMPAD9 | 69 | 105 | 小数字键盘9键 |
| VK_MULTIPLY | 6A | 106 | 乘号键 |
| VK_ADD | 6B | 107 | 加号键 |
| VK_SEPARATOR | 6C | 108 | 分割键 |
| VK_SUBSTRACT | 6D | 109 | 减号键 |
| VK_DECIMAL | 6E | 110 | 小数点键 |
| VK_DIVIDE | 6F | 111 | 除号键 |
| VK_F1 | 70 | 112 | F1键 |
| VK_F2 | 71 | 113 | F2键 |
| VK_F3 | 72 | 114 | F3键 |
| VK_F4 | 73 | 115 | F4键 |
| VK_F5 | 74 | 116 | F5键 |
| VK_F6 | 75 | 117 | F6键 |
| VK_F7 | 76 | 118 | F7键 |
| VK_F8 | 77 | 119 | F8键 |
| VK_F9 | 78 | 120 | F9键 |
| VK_F10 | 79 | 121 | F10键 |
| VK_F11 | 7A | 122 | F11键 |
| VK_F12 | 7B | 123 | F12键 |
| VK_F13 | 7C | 124 | F13键 |
| VK_F14 | 7D | 125 | F14键 |
| VK_F15 | 7E | 126 | F15键 |
| VK_F16 | 7F | 127 | F16键 |
| VK_F17 | 80 | 128 | F17键 |
| VK_F18 | 81 | 129 | F18键 |
| VK_F19 | 82 | 130 | F19键 |
| VK_F20 | 83 | 131 | F20键 |
| VK_F21 | 84 | 132 | F21键 |
| VK_F22 | 85 | 133 | F22键 |
| VK_F23 | 86 | 134 | F23键 |
| VK_F24 | 87 | 135 | F24键 |
| VK_NUMLOCK | 90 | 144 | Num Lock键 |
| VK_SCROLL | 91 | 45 | Scroll Lock键 |
| VK_LSHIFT | A0 | 160 | 左Shift键 |
| VK_RSHIFT | A1 | 161 | 右Shift键 |
| VK_LCONTROL | A2 | 162 | 左Ctrl键 |
| VK_RCONTROL | A3 | 163 | 右Ctrl键 |
| VK_LMENU | A4 | 164 | 左Alt键 |
| VK_RMENU | A5 | 165 | 右Alt键 |
网页防止打印屏蔽
F12打开控制台,Elements中的EventListeners标签中keyup事件Remove掉,然后Ctrl+P打印即可。
volatile防止编译器优化
warning: #550-D: variable "d" was set but never used 描述:变量'd'定义但从未使用,或者是,虽然这个变量你使用了,但编译器认为变量d所在的语句没有意义,编译器把它优化了。
解决:仔细衡量所定义的变量d是否有用,若是认定变量d所在语句有意义,那么尝试用volatile关键字修饰变量d,若是真的没有用,那么删除掉以释放可能的内存。
此时模拟调试时显示此变量值会显示not in scope。
下载网上的流媒体资源
目前常见的流媒体格式基本上都是(至少我见过的只有)flv和list形式的,像flv这种的整体流媒体文件可以直接抓包把绝对地址找出来,而list形式的流媒体是一小段一小段的媒体文件,而且大部分都进行过加密,本文就以典型的m3u8流媒体形式为例,走一遍下载的过程。
- 1.首先在浏览器监视中找到包含所有ts的m3u8文件,(一般只有一个,有时候会又两个,只用那个信息完整的),如果有key的话把key也当下来。
- 2.想办法把所有ts文件当下来,我是用迅雷直接新建批量任务,因为ts文件的地址都是一样的,只是最后文件的标号不一样,也可以写个py批量下。如果网站服务器够好的话可以直接用 .\ffmpeg -i 地址.m3u8 -c copy .\2.mkv,这样省时省力,不过除了比较大的教育网站,其他小网站用这个下会慢死。
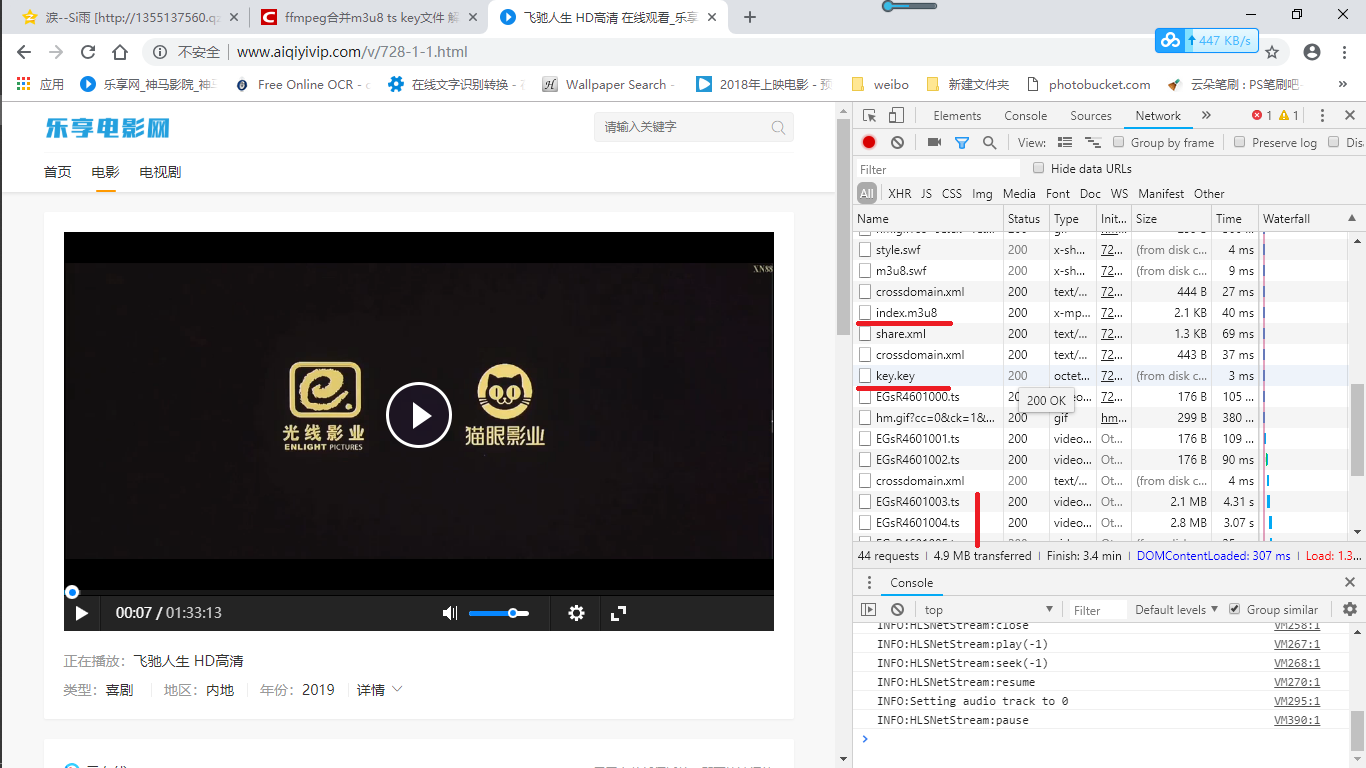
- 3.最后自己本地有的是一个m3u8、一个key、一堆ts文件了。
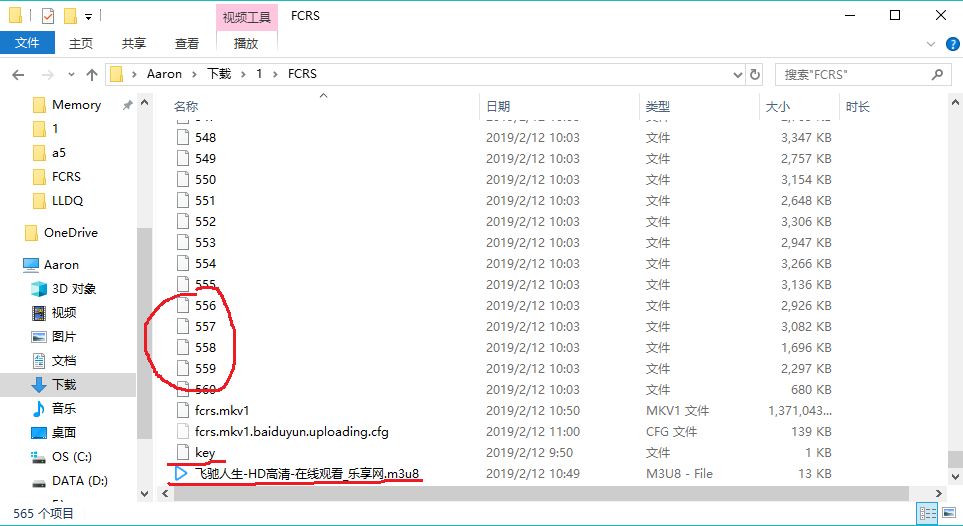
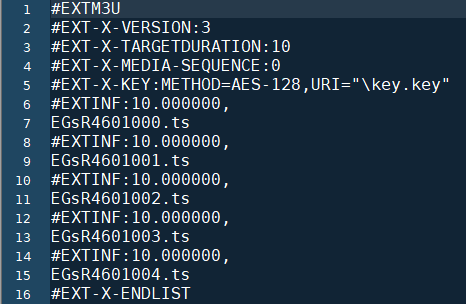
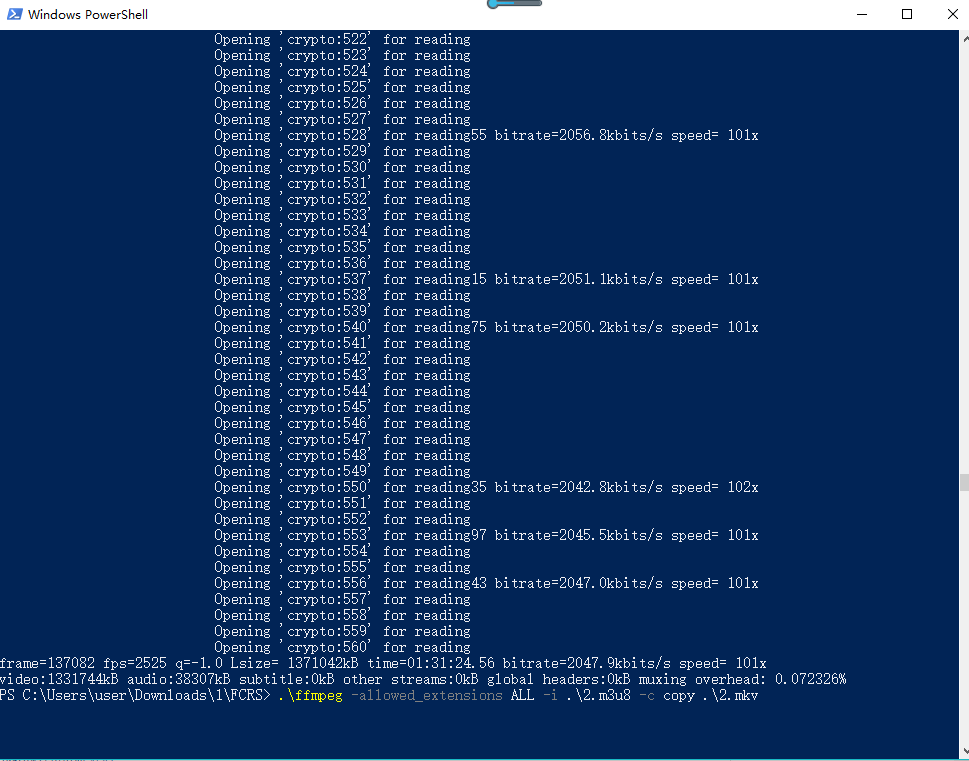
- 4.把m3u8里的list路径改为本地路径,保存一下,然后在cmd或shell里用ffmpeg转就行了“.\ffmpeg -allowed_extensions ALL -i .\2.m3u8 -c copy .\2.mkv”,加ALL是为了读key文件。
Node快速切换版本、版本回退(降级)、版本更新(升级)(2021-09-27)
解决方案一(n)
(1)安装node版本管理模块n
sudo npm install n -g下边步骤请根据自己需要选择。
(2)安装稳定版
sudo n stable(3)安装最新版
sudo n latest(4) 版本降级/升级
sudo n 版本号(5)检测目前安装了哪些版本的node
n(6)切换版本(不会删除已经安装的其他版本)
n 版本号(7)删除版本
sudo n rm 版本号输入密码,回车即可删除指定版本。
提示:
演示系统:macOS High Sierra 10.13.2;sudo是mac下输入密码验证身份的命令,因此windows用户应该是以管理员身份运行命令行工具,然后删除sudo即可。
举个例子:删除版本mac下是sudo n rm 版本号,windows下应该是n rm 版本号。
解决方案二(nvm)
1)启动终端,
cd ~,随后输入curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.33.6/install.sh | bash- 2)创建.bash_profile:输入
touch .bash_profile - 3)编辑.bash_profile文件:输入
open .bash_profile 4)在弹出的.bash_profile文件内增加
export NVM_DIR="$HOME/.nvm" [ -s "$NVM_DIR/nvm.sh" ] && . "$NVM_DIR/nvm.sh" # This loads nvm- 5)终端键入
command -v nvm,回车,如果输出了`nvm。代表已经安装成功。 6)命令
nvm install stable //安装最新版 node nvm install [node版本号] //安装指定版本的node nvm ls // 查看已安装版本 nvm use [node版本号] //切换到指定版本的node nvm alias default [node版本号] //设置默认版本nvm使用详情可参考:https://github.com/creationix/nvm
Node快速切换版本、版本回退(降级)、版本更新(升级) - ECMAScripter - 脚本之家
Ubuntu代号版本(2021-09-27)
| Ubuntu版本号 | Ubuntu代号 | debian版本号 | debian代号 |
|---|---|---|---|
| 14.04 LTS | Trusty | 8 | jessie |
| 16.04 LTS | Xenial | 9 | strech |
| 18.04 LTS | Bionic | 10 | buster |
| 20.04 LTS | Focal | 11 | Bullseye |
常用语言API文档
JSON简介(2018-06-01)
JSON(JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。它基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。
JSON 语法规则
在 JS 语言中,一切都是对象。因此,任何支持的类型都可以通过 JSON 来表示,例如字符串、数字、对象、数组等。但是对象和数组是比较特殊且常用的两种类型:
对象表示为键值对
数据由逗号分隔
花括号保存对象
方括号保存数组
JSON 键/值对
JSON 键值对是用来保存 JS 对象的一种方式,和 JS 对象的写法也大同小异,键/值对组合中的键名写在前面并用双引号 "" 包裹,使用冒号 : 分隔,然后紧接着值:
{"firstName": "Json"}这很容易理解,等价于这条 JavaScript 语句:
{firstName : "Json"}
JSON 与 JS 对象的关系
很多人搞不清楚 JSON 和 Js 对象的关系,甚至连谁是谁都不清楚。其实,可以这么理解:JSON 是 JS 对象的字符串表示法,它使用文本表示一个 JS 对象的信息,本质是一个字符串。如:
var obj = {a: 'Hello', b: 'World'}; //这是一个对象,注意键名也是可以使用引号包裹的
var json = '{"a": "Hello", "b": "World"}'; //这是一个 JSON 字符串,本质是一个字符串
JSON 和 JS 对象互转
要实现从对象转换为 JSON 字符串,使用 JSON.stringify() 方法:
var json = JSON.stringify({a: 'Hello', b: 'World'}); //结果是 '{"a": "Hello", "b": "World"}'要实现从 JSON 转换为对象,使用 JSON.parse() 方法:
var obj = JSON.parse('{"a": "Hello", "b": "World"}'); //结果是 {a: 'Hello', b: 'World'}
常用类型
在 JS 语言中,一切都是对象。因此,任何支持的类型都可以通过 JSON 来表示,例如字符串、数字、对象、数组等。但是对象和数组是比较特殊且常用的两种类型。
对象:对象在 JS 中是使用花括号包裹 {} 起来的内容,数据结构为 {key1:value1, key2:value2, ...} 的键值对结构。在面向对象的语言中,key 为对象的属性,value 为对应的值。键名可以使用整数和字符串来表示。值的类型可以是任意类型。
数组:数组在 JS 中是方括号 [] 包裹起来的内容,数据结构为 ["java", "javascript", "vb", ...] 的索引结构。在 JS 中,数组是一种比较特殊的数据类型,它也可以像对象那样使用键值对,但还是索引使用得多。同样,值的类型可以是任意类型。
Html5本地存储和本地数据库(2018-05-16)
Cookie
Cookie机制简介
Cookie技术是客户端的解决方案,Cookie就是由服务器发给客户端的特殊信息,而这些信息以文本文件的方式存放在客户端,然后客户端每次向服务器发送请求的时候都会带上这些特殊的信息。
即当用户使用浏览器访问一个支持Cookie的网站的时候,用户会提供包括用户名在内的个人信息并且提交至服务器;接着,服务器在向客户端回传相应的超文本的同时也会发回这些个人信息,当然这些信息并不是存放在HTTP响应体(Response Body)中的,而是存放于HTTP响应头(Response Header)。
当客户端浏览器接收到来自服务器的响应之后,浏览器会将这些信息存放在一个统一的位置,对于Windows操作系统而言,我们可以从: [系统盘]:\Documents and Settings[用户名]\Cookies目录中找到存储的Cookie;自此,客户端再向服务器发送请求的时候,都会把相应的Cookie再次发回至服务器。而这次,Cookie信息则存放在HTTP请求头(Request Header)了。
有了Cookie这样的技术实现,服务器在接收到来自客户端浏览器的请求之后,就能够通过分析存放于请求头的Cookie得到客户端特有的信息,从而动态生成与该客户端相对应的内容。
通常,我们可以从很多网站的登录界面中看到“请记住我”这样的选项,如果你勾选了它之后再登录,那么在下一次访问该网站的时候就不需要进行重复而繁琐的登录动作了,而这个功能就是通过Cookie实现的。
Cookie属性
String name:该Cookie的名称。Cookie一旦创建,名称便不可更改。
Object value:该Cookie的值。如果值为Unicode字符,需要为字符编码。如果值为二进制数据,则需要使用BASE64编码。
int maxAge:该Cookie失效的时间,单位秒。如果为正数,则该Cookie在>maxAge秒之后失效。如果为负数,该Cookie为临时Cookie,关闭浏览器即失效,浏览器也不会以任何形式保存该Cookie。如果为0,表示删除该Cookie。默认为–1。
boolean secure:该Cookie是否仅被使用安全协议传输。安全协议。安全协议有HTTPS,SSL等,在网络>上传输数据之前先将数据加密。默认为false。
String path:该Cookie的使用路径。如果设置为“/sessionWeb/”,则只有contextPath为“/sessionWeb”的程序可以访问该Cookie。如果设置为“/”,则本域名下contextPath都可以访问该Cookie。注意最后一个字符必须为“/”。
String domain:可以访问该Cookie的域名。如果设置为“.google.com”,则所有以“google.com”结尾的域名都可以访问该Cookie。注意第一个字符必须为“.”。
String comment:该Cookie的用处说明。浏览器显示Cookie信息的时候显示该说明。
int version:该Cookie使>用的版本号。0表示遵循Netscape的Cookie规范,1表示遵循W3C的RFC 2109规范。
Cookie修改删除
Cookie并不提供修改、删除操作。
如果要修改某个Cookie,只需要新建一个同名的Cookie,添加到response中覆盖原来的Cookie。
如果要删除某个Cookie,只需要新建一个同名的Cookie,并将maxAge设置为0,并添加到response中覆盖原来的Cookie。注意是0而不是负数。负数代表其他的意义。读者可以通过上例的程序进行验证,设置不同的属性。
注意:修改、删除Cookie时,新建的Cookie除value、maxAge之外的所有属性,例如name、path、domain等,都要与原Cookie完全一样。否则,浏览器将视为两个不同的Cookie不予覆盖,导致修改、删除失败。
浏览器可以使用脚本程序如JavaScript或者VBScript等操作Cookie。例如下面的代码会输出本页面所有的Cookie。
<script>document.write(document.cookie);</script>
会话级别的本地存储:sessionStorage
sessionStorage提供了四个方法:
(1)setItem(key,value):添加本地存储数据。
(2)getItem(key):通过key获取相应的Value。
(3)removeItem(key):通过key删除本地数据。
(4)clear():清空数据。
永久本地存储:localStorage
localStorage提供了四个方法:
(1)setItem(key,value):添加本地存储数据。
(2)getItem(key):通过key获取相应的Value。
(3)removeItem(key):通过key删除本地数据。
(4)clear():清空数据。
本地数据库
详细介绍:
理解Cookie和Session机制
Html5本地存储和本地数据库
HTML/CSS系统学习(2018-03-21)
学习整理自 W3school,后期将整理至独立文章。
刚学前端改的一个小网站:O_MengZe初代博客A1,实用性不怎么强,但集成了一些js,看上去还是挺炫的……
对JSON和XML的基本理解(2017-12-04)
"说白了,不管是xml还是json,都只是包装数据的不同格式而已,重要的是其中含有的数据,而不是包装的格式。"
(引自知乎用户华子)
例如有一个人的信息要进行传送:
年龄15岁,性别男,爱好女。
那么用XML这种数据格式的话可以是
<person age="15" sex="male" like="famale" />
或者
<person>
<age value="15"/>
<sex value="male"/>
<like value="famale"/>
</person>用JSON描述为
{
"age":"15",
"sex":"male",
"like":"famale"
}
评论已关闭